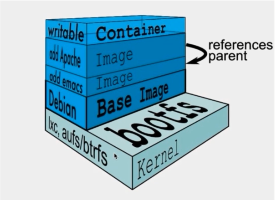
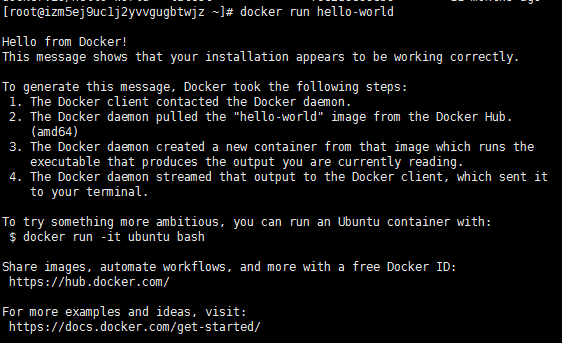
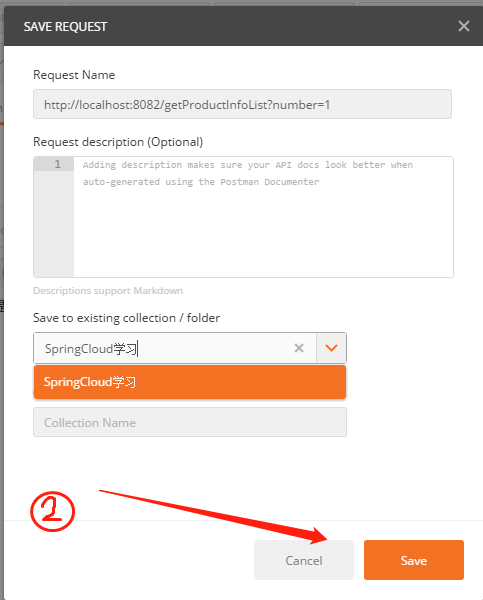
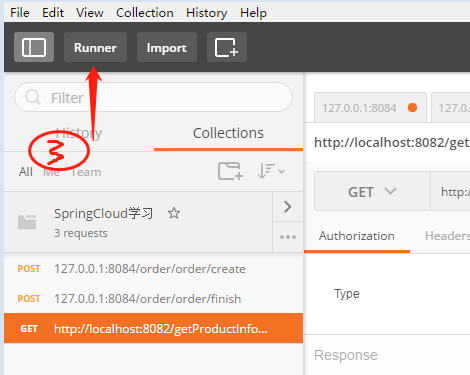
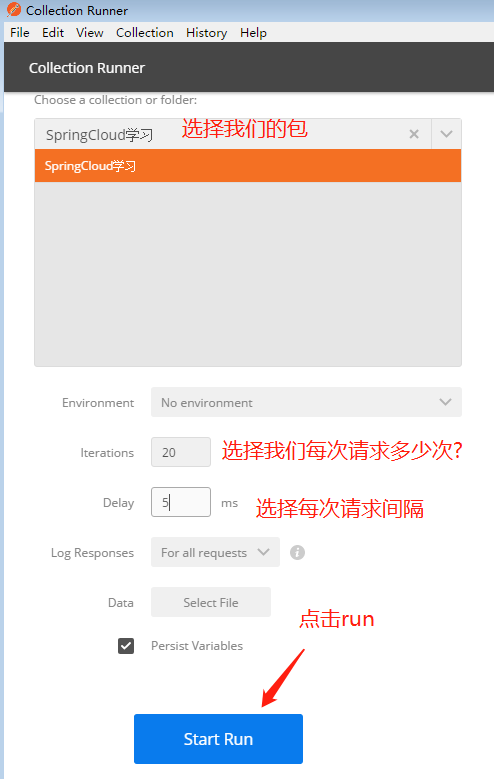
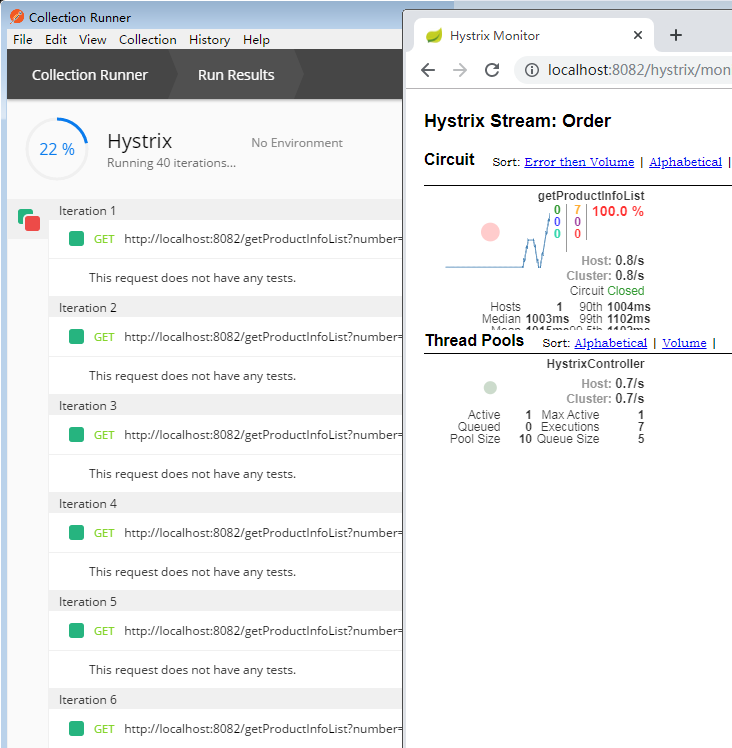
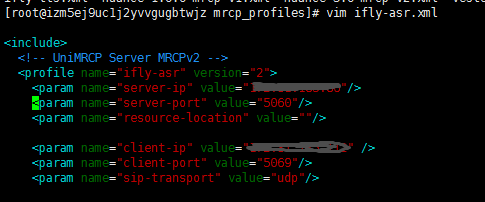
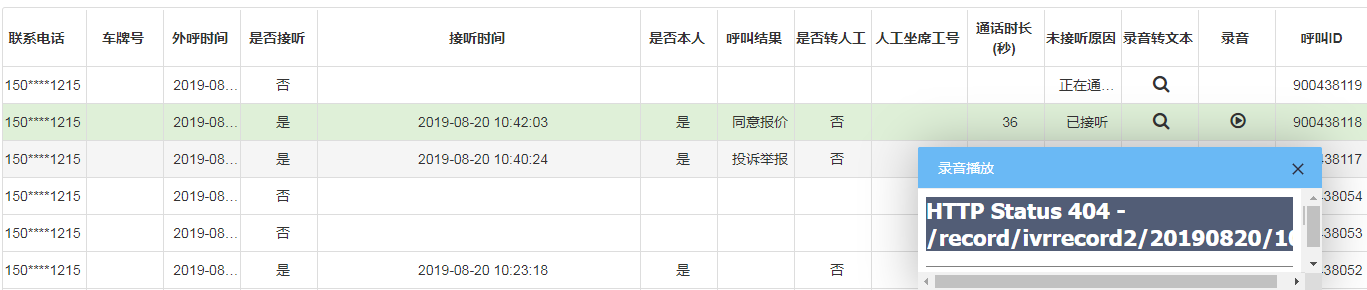
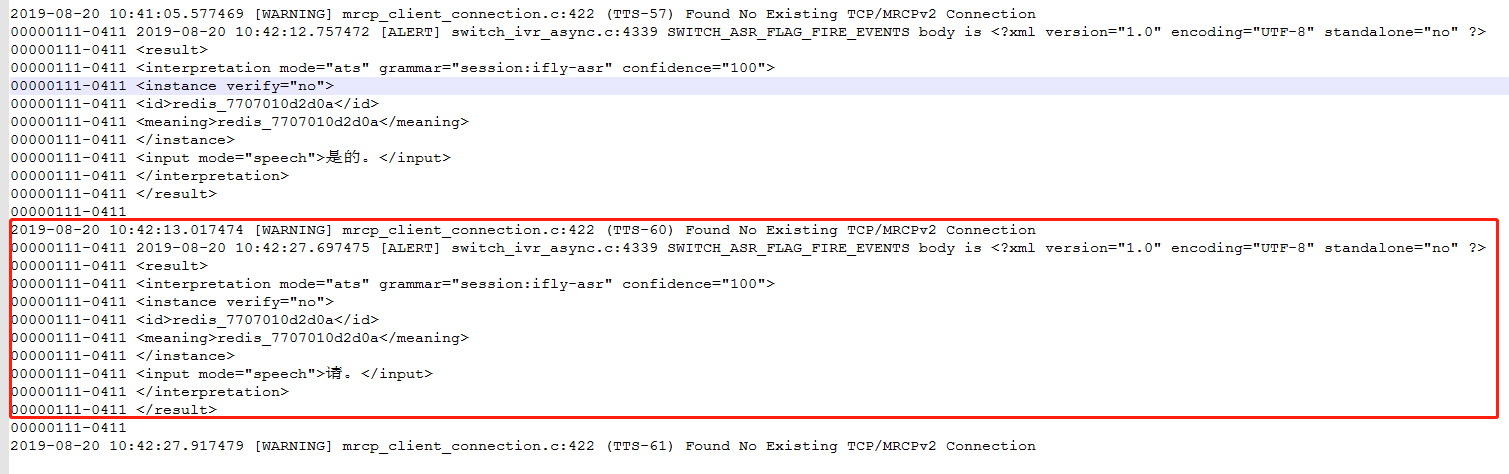
linux下安装完之后,如果执行docker version出现:Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? 说明docker服务没有起来。我们需要执行如下指令:
2019-12-15 08:15:41.058 DEBUG [order,dc93086b3bb2856a,eec9e8de8adb4274,false] 16616 --- [strix-product-2] o.s.c.openfeign.support.SpringEncoder : Writing [[DecreaseStockInput{productId='157875227953464068', productQuantity=2}]] using [org.springframework.http.converter.json.MappingJackson2HttpMessageConverter@d43328]
Hibernate: select ordermaste0_.order_id as order_id1_1_0_, ordermaste0_.buyer_address as buyer_ad2_1_0_, ordermaste0_.buyer_name as buyer_na3_1_0_, ordermaste0_.buyer_openid as buyer_op4_1_0_, ordermaste0_.buyer_phone as buyer_ph5_1_0_, ordermaste0_.create_time as create_t6_1_0_, ordermaste0_.order_amount as order_am7_1_0_, ordermaste0_.order_status as order_st8_1_0_, ordermaste0_.pay_status as pay_stat9_1_0_, ordermaste0_.update_time as update_10_1_0_ from order_master ordermaste0_ where ordermaste0_.order_id=?
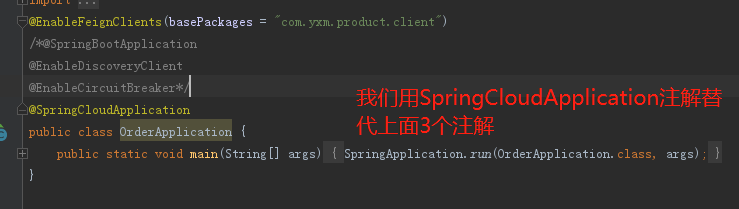
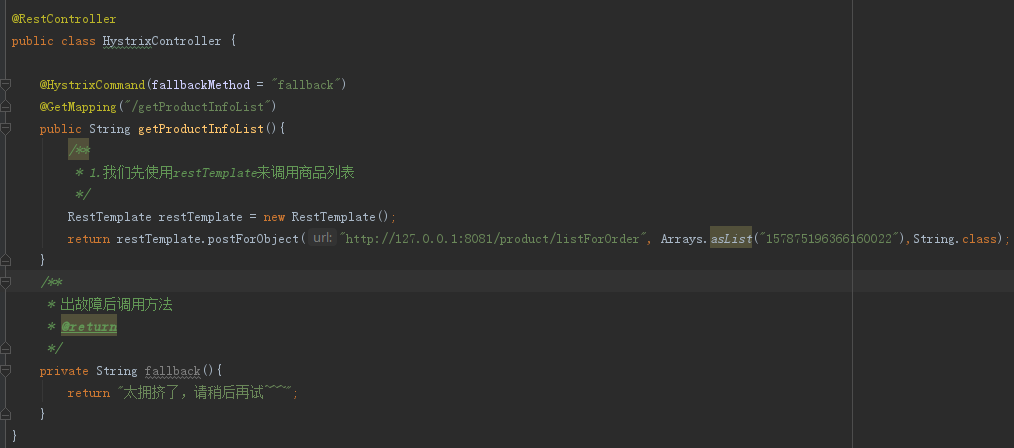
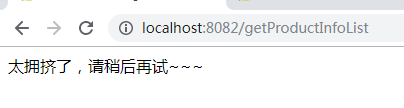
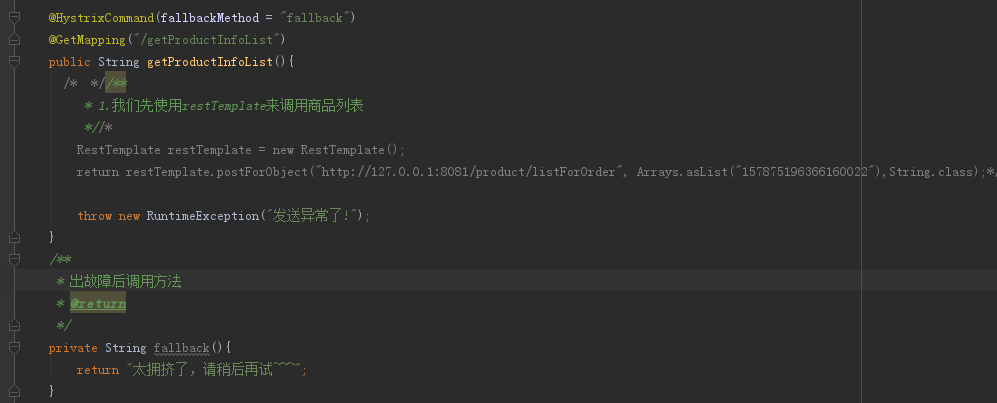
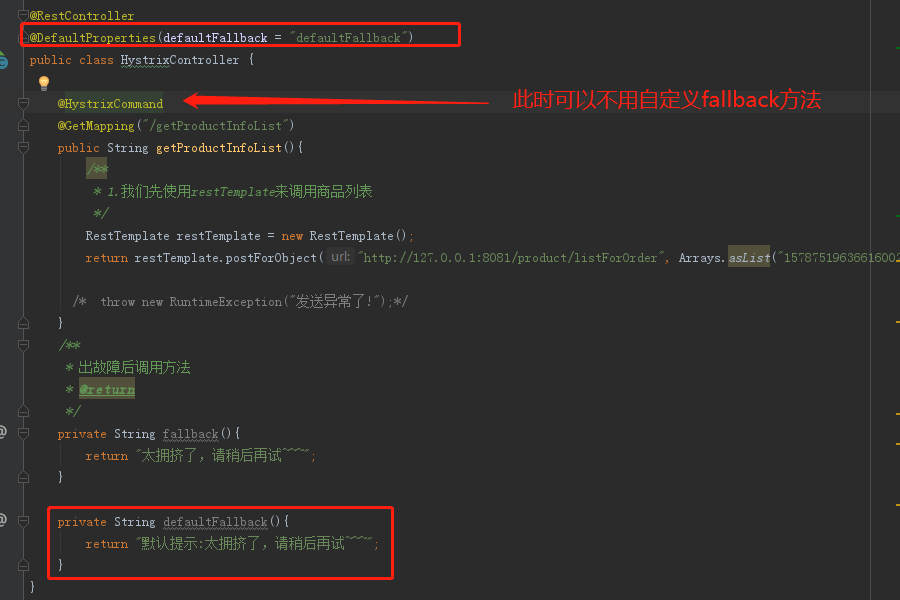
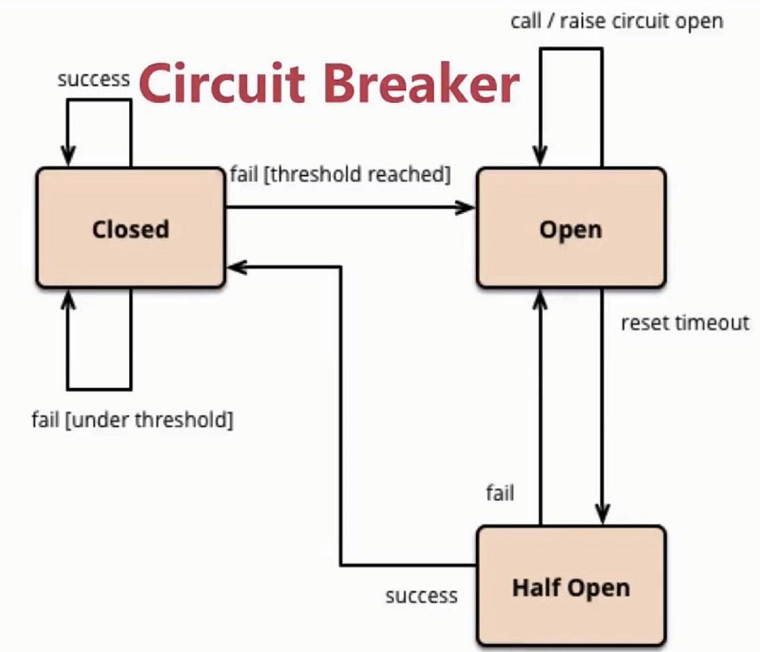
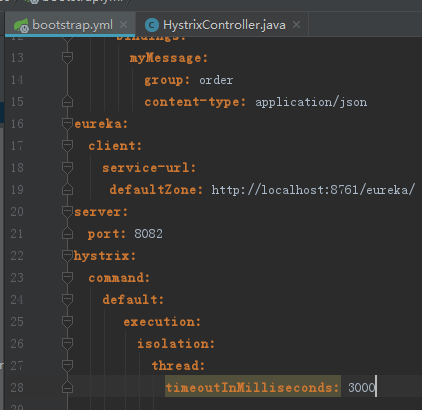
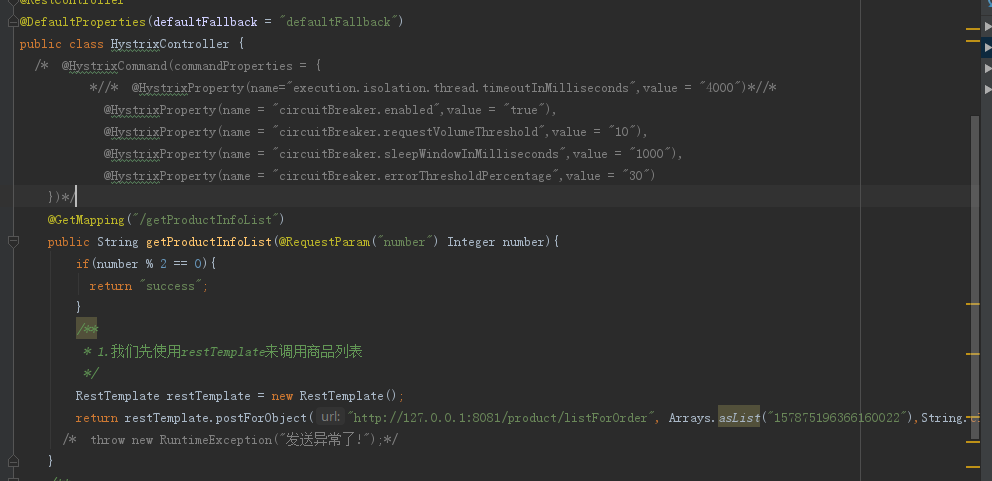
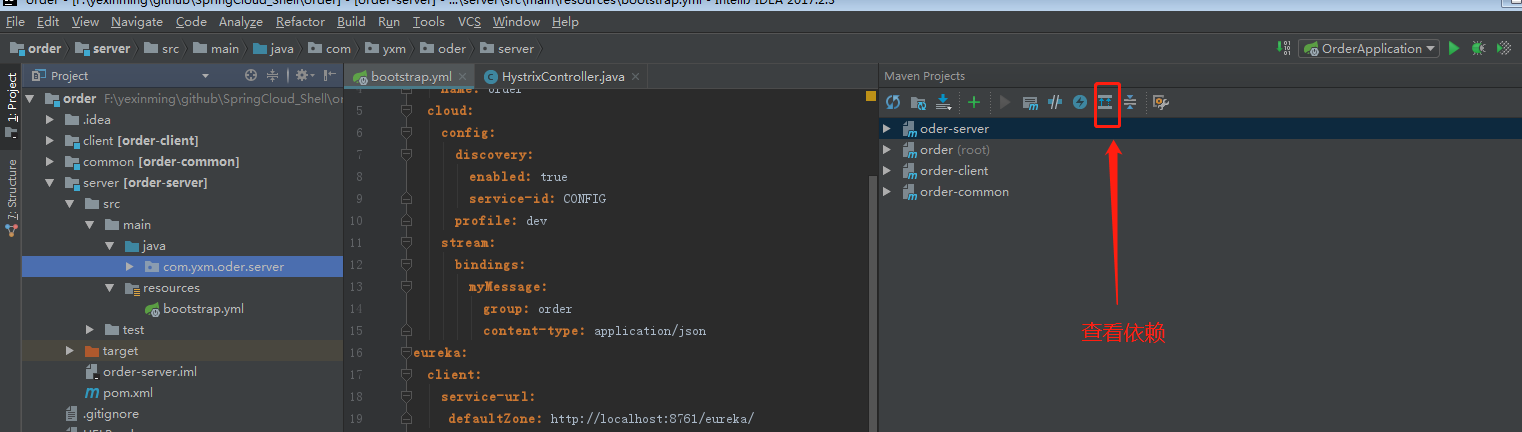
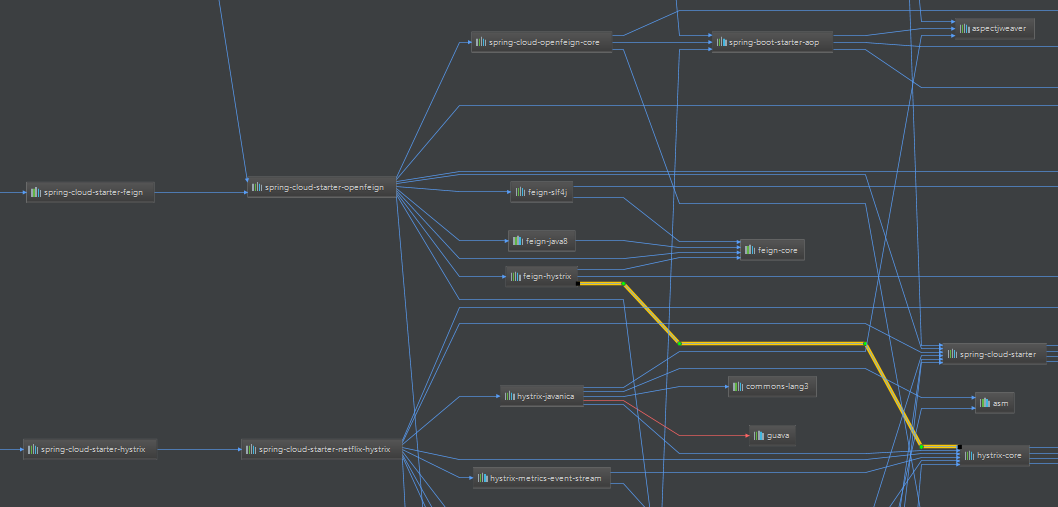
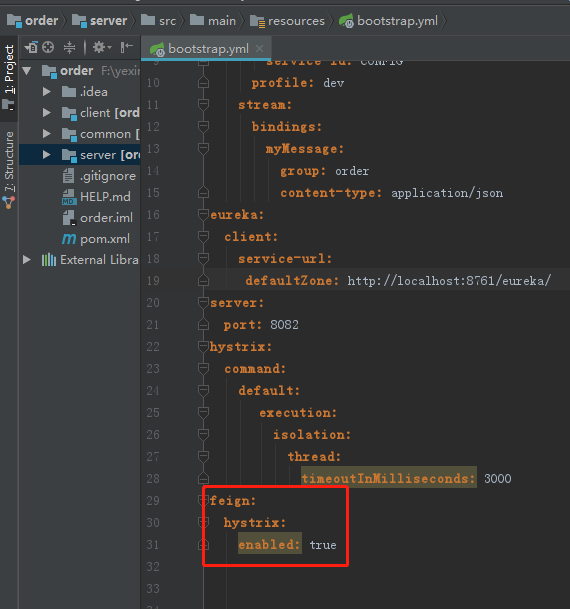
2.SpringCloud家族中防雪崩的利器就是:SpringCloud Hystrix,它是基于Netflix的开源框架(Hystrix的中文意思是豪猪:defend you app);Hystrix目的就是给微服务提供一系列服务容错保护机制;还记得Eureka的意思吗?Eureka就是找到了,也就是服务注册中心
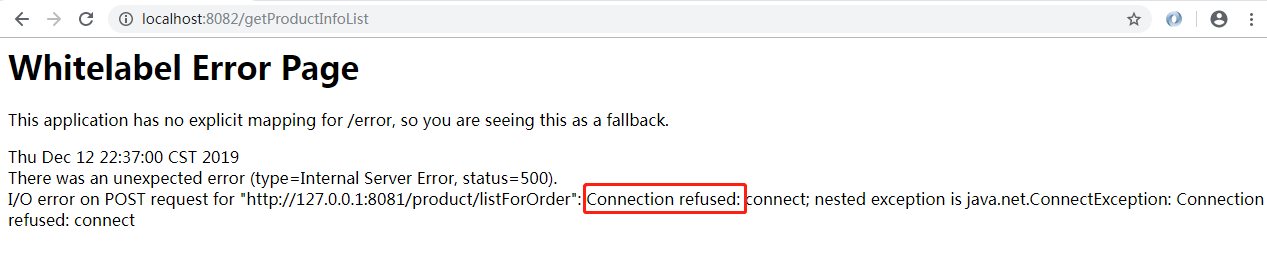
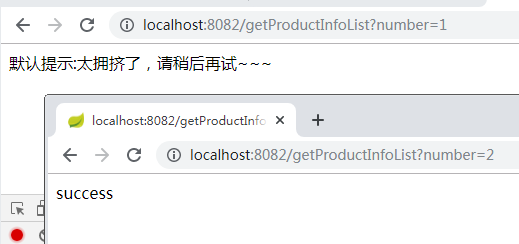
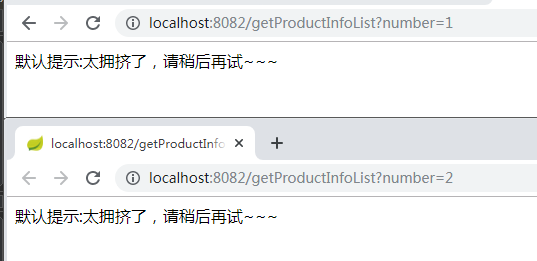
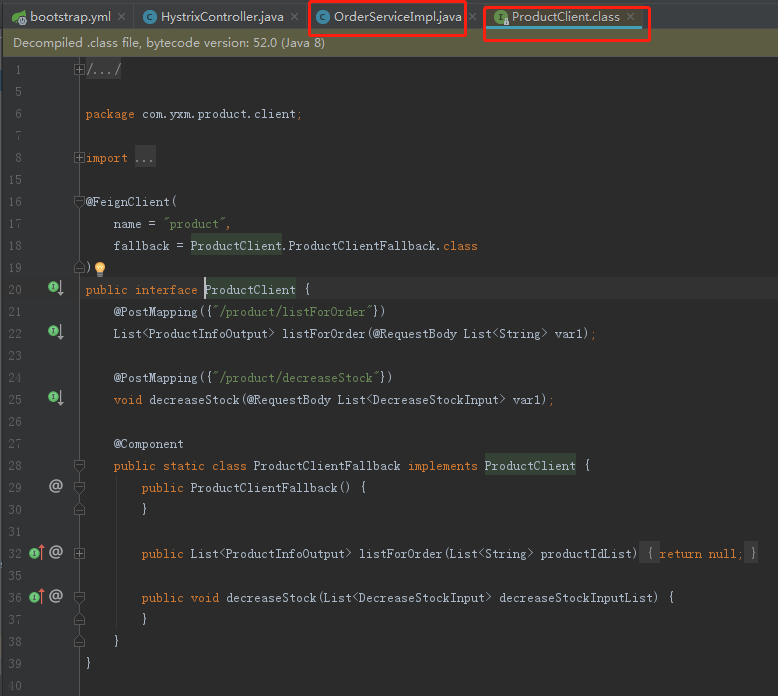
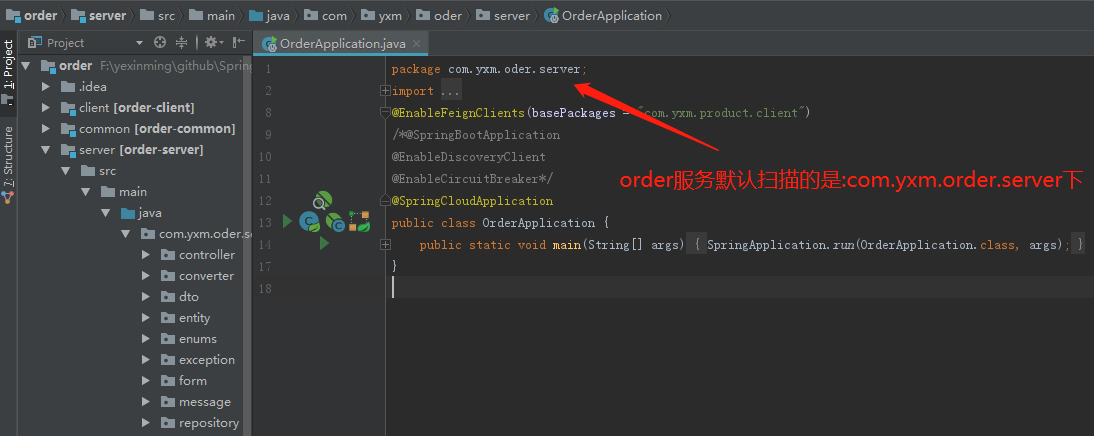
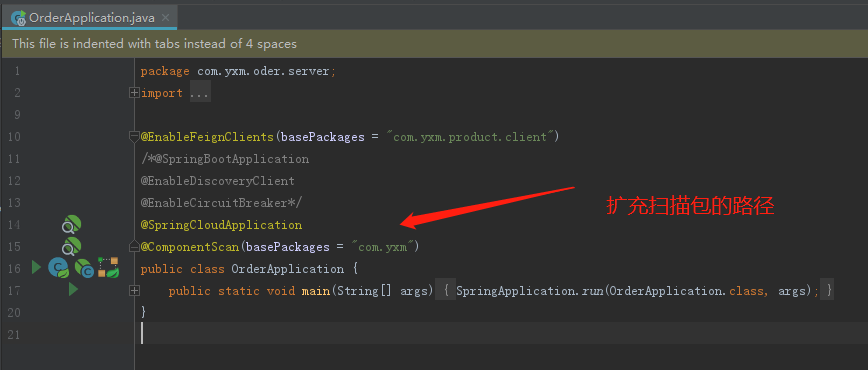
启动order服务,我们发现报错了: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name ‘orderServiceImpl’: Unsatisfied dependency expressed through field ‘productClient’; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘com.yxm.product.client.ProductClient’: FactoryBean threw exception on object creation; nested exception is java.lang.IllegalStateException: No fallback instance of type class com.yxm.product.client.ProductClient$ProductClientFallback found for feign client product
SELECT ob.customer_name,ob.customer_phone,ob.car_no,ob.cust_id FROM ocm_buslist ob
LEFT JOIN cti_cdr cdr ON ob.list_id = cdr.memberid
WHERE ob.event_id = xxx AND cdr.id IS NULL ORDER BY ob.list_id DESC
2.ocm_base_shbo处理:[删除未拨打的数据,删除之前先查询] a.查询未拨打的数据:
1
2
3
4
5
6
SELECT sb.* FROM ocm_base_shbo sb WHERE sb.event_id = xxx AND sb.cust_id IN (SELECT DISTINCT ob.cust_id FROM ocm_buslist ob
LEFT JOIN cti_cdr cdr ON ob.list_id = cdr.memberid
WHERE ob.event_id = xxx AND cdr.id IS NULL);
```
b.删除未拨打数据:
DELETE FROM ocm_base_shbo WHERE event_id = xxx AND cust_id IN (SELECT ob.cust_id FROM ocm_buslist ob LEFT JOIN cti_cdr cdr ON ob.list_id = cdr.memberid WHERE ob.event_id = xxx AND cdr.id IS NULL);
1
2
3
3. 3.ocm_buslist处理:[删除未拨打的数据,删除之前先查询]
a.查询未拨打数据
select * FROM ocm_buslist WHERE event_id = xxx AND list_id NOT IN (SELECT DISTINCT memberid FROM cti_cdr WHERE notifyid = xxx);
1
2
b.删除未拨打数据
DELETE FROM ocm_buslist WHERE event_id = xxx AND list_id NOT IN (SELECT DISTINCT memberid FROM cti_cdr WHERE notifyid = xxx);
1
2
4. 4.最后导入数据,修改批次统计:
select * from ocm_event_statistics where event_id = xxx
SELECT event_id,event_state,event_name,send_time,over_time FROM ocm_event WHERE event_id IN (SELECT DISTINCT event_id FROM ocm_buslist_timing WHERE call_next_time
1
2
### 4.查看某个租户是否配置了重呼轮呼策略
SELECT enti.id,enti.entname,enti.state,oc.id,oc.parameter FROM cti_entinfo enti LEFT JOIN ocm_after_call_action oc ON enti.id = oc.entid